


System Design Tiny URL : A URL Shortening Service

A tiny URL is a shortened version of a URL, which is also known as a web address or link. The purpose of a tiny URL is to create a shorter and easier-to-share version of a long and complex URL. This is particularly useful when sharing links on social media platforms or other digital communication channels, where the character limit may be limited.
The process of creating a tiny URL involves taking the original long URL and compressing it into a much shorter format. This is typically done using a URL shortener service, which generates a unique shortened URL that redirects to the original long URL when clicked.
Tiny URLs are often used in marketing campaigns to make it easier for customers to remember and share product or service links. They are also used in other applications, such as analytics tracking or affiliate marketing, where it is important to track the source of a click or conversion.
Functional Requirement
Allow users to create short/tiny URLs from long URLs.
Ensure that clicking on a short/tiny URL redirects the user to the original URL.
Implement an expiration time for short/tiny URLs to automatically expire after a set period.
Nonfunctional Requirement
High availability is critical for the system to prevent short URL failures.
The system should be highly scalable to handle a large number of users and URL requests.
The system should be designed to support eventual consistency to ensure high availability, even if data replication takes some time.
URL redirection should occur in real-time to ensure a seamless user experience.
The system should be optimized for quick-read operations since it is read-heavy.
The Long URLs should have a maximum limit of 500 characters.
The short URLs generated by the system should have a maximum limit of 8 to 9 characters.
Each short URL should have an expiration time of one year.
Capacity Estimation
Assuming a global population of 7.3 billion, let's consider an active user base of 500 million. On average, each user creates one tiny new URL every week. Therefore, the total number of new URLs generated per month is:
500 million * 4 = 2 billion URLs
Total generated URLs for a period of 5 years
2 billion * 12 * 5 = 120 billion URLs
The ratio of read requests to new URL creation is 100:1. So, we can estimate the number of read requests as:
200 billion read requests
This translates to approximately 800 URLs(Write QPS) generated per second and 80,000(Read QPS) read requests per second.
To store all the generated URLs for a period of 5 years, we need a storage capacity of approximately:
2 billion * 500 bytes per URL * 5 * 12 = 60 terabytes
Given the need for good internet bandwidth, we estimate that the read request rate would be around 40 megabytes per second, while the write request rate would be around 400 kilobytes per second.
To optimize performance, we can employ an 80:20 rule, caching the 20% of hot URLs that generate 80% of the read traffic.
API Design
To create a short URL from a long URL, use the following API endpoint:
HTTP Method: POST
Endpoint: /api/url
Request Body: longUrl (string)
Response: tinyID (string)
Response code: 200 (OK)
To retrieve the long URL from a short URL, use the following API endpoint:
HTTP Method: GET
Endpoint: /api/url/{tinyID}
Path Parameter: tinyID (string)
Response: longUrl (string)
Response code: 302
Database Design
UserTable
User id (partition key): unique identifier for each user
Name: name of the user
LastLogin: timestamp of the user's last login
IP address: IP address of the user's last login
TinyURL
Tiny ID (Partition Key): a unique identifier for the tiny URL
longURL: corresponding long URL for the tiny URL
CreatedAt: timestamp when the long URL was created
ExpiredAt: timestamp when the long URL will expire
We have decided to use a NoSQL database like Cassandra for our system due to the following reasons:
We are comfortable with eventual consistency and NoSQL databases provide this option.
There will be a high volume of write requests and NoSQL databases are better suited for write-heavy workloads.
Partitioning and sharding are not available out of the box in SQL databases, which may cause scaling issues.
SQL databases are designed for strong consistency, but we are willing to sacrifice this for high availability, which is easier to achieve with a NoSQL database like Cassandra.
System Design
Techniques to generate unique tiny id of 8 characters
MD5 hash or SHA 256
One approach to generate a unique key for a given URL is to use a hash function such as MD5 or SHA-256. MD5 generates a 128-bit hash, which can then be encoded using BASE 64 [a-zA-Z0-9] and +,/ characters. Each character in BASE 64 encodes 6 bits, so the 128-bit hash will result in a string of 21 to 22 characters. However, since we want our tiny ID to be only 8 characters long, we can take the first 8 characters of the encoded string. This approach may result in duplication problems where different URLs may have the same short key.
The current approach of taking only the first 8 characters of the unique key can lead to duplication, resulting in different URLs having the same short key. This may not be acceptable since a short key may have been blacklisted or spammed by a user in the past, while the underlying long URL is legitimate. Additionally, if multiple users create short URLs for popular services, the resulting short URL may be spammed by many users. Therefore, it may not be advisable to return the same short URL.
BASE 64 Encoding of Integers
We can generate a series of integers as strings from 1 to 1 trillion and then use base 64 encoding to obtain a tiny ID for our long URL. However, there is a risk of security concerns as users may be able to guess the next tiny ID due to the simplicity of the generation algorithm. This is why in the first approach, we utilized MD5 or SHA256 before performing base 64 encodings.
Key Generation Service(KGS)
We can establish a specialized service for generating and storing unique keys in databases. This service can have two tables - UsedKeys and FreshKeys. When an application server requires a key, it can request it from the Key Generation Service. Therefore, each application server can retrieve keys from the Key service in advance and store them in a cache. Before returning a batch of keys from FreshKeys, this service should update all keys in UsedKeys. Additionally, the service can continuously generate new unique keys in the background and update them in the FreshKeys table.
However there are few downsides of this approach:The dependency on an external service for key generation can cause network calls to slow down our system's latency.
Additionally, KSG can become a single point of failure, although this can be prevented by implementing a failover server.
Another disadvantage is the need to maintain a separate server for this relatively small functionality.
UUID Generation
Each framework/library provides a UUID generation process that produces a 128-bit identifier, which results in a tiny ID that is typically 22 characters long after base 64 encoding. However, since this is too long for our needs
Distributed tiny Id generation
We can develop a custom tiny ID generater.
Example:- https://www.callicoder.com/distributed-unique-id-sequence-number-generator/To generate a unique ID, we can divide the tiny ID into three parts:
Time in seconds
Node ID
Counter
Assuming we want to generate unique URLs for 50 years, we must calculate the total number of seconds in that period, which is approximately 50* 365 * 86400 ~= 25 * 10^8 seconds ~= 2^32 bits. To represent these seconds, we require 32 bits.
We can allocate the first 32 bits to represent the time in seconds, which will start from a custom epoch. Assuming we will have 16 write instances in the future, we can use the next 4 bits to represent the node ID. We can use the last 12-bit counter for the counter.
Therefore, the total number of bits required to generate the tiny ID is 48 bits, which is approximately equal to 8 characters long after Base 64 encoding.
This approach appears to be the most suitable approach to consider in system design as it does not present any issues compared to previous approaches.
How can we prevent generating different tiny IDs for the same long URL, If it is an interviewer ask?
One possible answer could be to maintain a mapping between long URLs and their corresponding tiny IDs in a database. Before generating a new tiny ID for a long URL, we can check if the long URL already exists in the database. If it does, we can return the existing tiny ID instead of generating a new one. This will ensure that the same long URL always maps to the same tiny ID, and we do not end up with multiple tiny IDs for the same long URL.
We can use the following table to maintain a mapping between a long URL and its corresponding tiny ID:
LongUrlToTinyId Table
longUrl: the long URL, used as the partition key
tinyId: the corresponding tiny ID
createdAt: the timestamp when the mapping was created
This table can be used to check if a long URL already has a corresponding tiny ID. If it does, the existing tiny ID can be returned instead of generating a new one.
We have two options to maintain the mapping between LongUrlToTinyId and TinyURL table.
We can either write synchronously to the LongUrlToTinyId table while writing into the TinyURL table, which may increase the write latency of our system.
Alternatively, we can use the Change Data Capture pattern to populate the LongUrlToTinyId table.
However, the 2nd approach may take a few seconds to update the table. In a hypothetical scenario where another user wants to generate a tiny URL for the same long URL during this time and the LongUrlToTinyId table is not yet updated, it may lead to generating another unique ID for the same long URL.
To prevent this, we can implement locking with some TTL in the Redis cache. Therefore, every write request has to check the Redis cache to see if there is already an ongoing write request for the same long URL.
If yes, we can block that request in the cache itself by not giving a lock on that key.
If the lock is not found in the Redis cache, then the request will proceed to the application server. The server will check the LongUrlToTinyId table to see if the long URL already has a corresponding tiny ID. If a mapping is found, then the server will return the existing tiny ID to the client. If a mapping is not found, then we can safely assume it is a new tiny URL generation request.
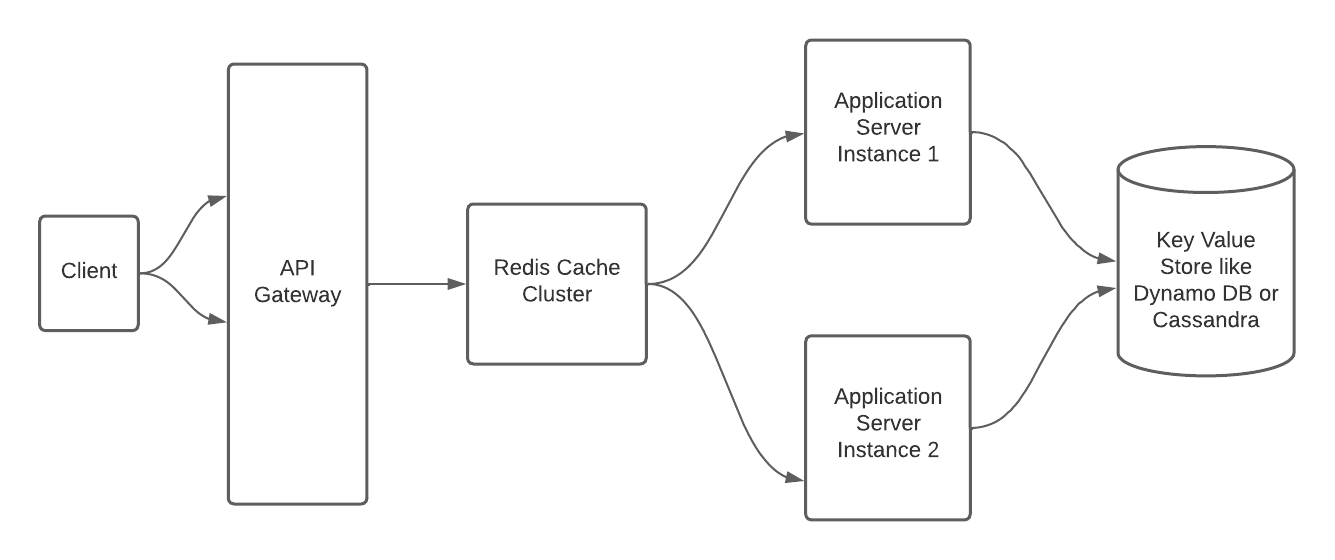
Caching
If we assume that 80% of the read traffic is generated by 20% of the hot URLs, and we have 80,000 read requests per second, then in one day we would have:
80,000 * 86400 = 6,912,000,000 read requests per day
To cache 20% of these requests, we would need to cache:
20% of 6,912,000,000 = 1,382,400,000 requests per day
Assuming an average URL size of 100 bytes, the total size of the cache would be:
1,382,400,000 * 100 bytes = 138,240,000,000 bytes
Which is approximately 128.75 GB.
Therefore, we would need at least 129 GB of memory to cache 20% of the hot URLs.